
- Daybreak Expansion: OpenAI is turning its Daybreak initiative into a defensive cybersecurity program with GPT-5.5-Cyber, Codex updates, Patch the Planet, and partner access.
- Access Limits: GPT-5.5-Cyber remains limited to verified defenders under monitoring and guardrails rather than ordinary public access.
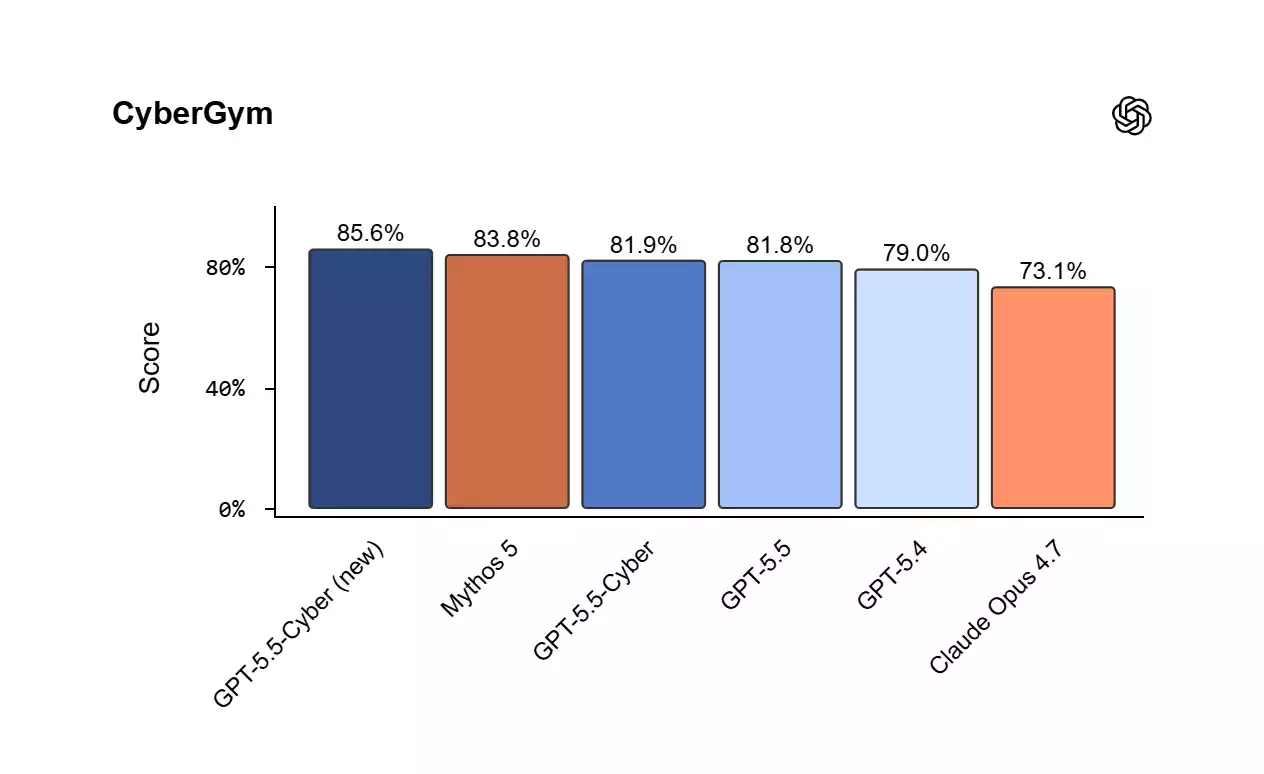
- Benchmark Signal: OpenAI places GPT-5.5-Cyber at 85.6% on CyberGym, ahead of Anthropic’s closed Mythos 5 system, but the score is controlled-test evidence.
- Open-Source Test: Patch the Planet will be judged by whether projects such as cURL, Go, Python, Sigstore, and pyca/cryptography receive reviewable fixes.
OpenAI is now turning its Daybreak initiative into a defensive cybersecurity program that combines Codex updates, the GPT-5.5-Cyber release and partner access for approved organizations.
As OpenAI points out, its GPT-5.5-Cyber model reached 85.6% on CyberGym, a controlled benchmark for AI work on software vulnerability tasks. OpenAI’s comparison places the model ahead of Anthropic’s closed Mythos 5 cybersecurity system, while access remains limited rather than self-serve.
Daybreak’s earlier enterprise-security launch focused on finding flaws in complex code. With a restricted rollout, OpenAI keeps GPT-5.5-Cyber limited to verified defenders under monitoring and guardrails.
What GPT-5.5-Cyber Adds to Daybreak
OpenAI is combining GPT-5.5-Cyber, Codex Security, its Patch the Planet initiative, and partner access into one defensive cybersecurity program. Daybreak’s practical pitch is not another scanner product but a workflow that connects finding a vulnerability with confirming and fixing it, while keeping the strongest model behind identity checks and approved-use rules.
Codex Security’s earlier research preview focused on finding flaws. For human review, a new Codex Security plugin can now generate reports, trace attack paths, build threat models, validate findings, and produce codebase-specific fix candidates that engineers can inspect before committing code.
Daybreak work has already surfaced vulnerabilities across Linux, OpenBSD, FreeBSD, dnsmasq, HTTP/2 implementations, Chrome, Safari, and Firefox. Affected software spans operating systems, networking components, and browsers, so the review burden moves quickly from model output to proof, reproducibility, and safe code changes.
OpenAI also says that Codex Security has already scanned more than 30 million commits across more than 30,000 codebases since the preview. Scan volume gives the program a scale marker, but it remains unclear how many findings survive triage, match real attack paths, and arrive with tests.
OpenAI’s CyberGym benchmark results list GPT-5.5-Cyber at 85.6% and standard GPT-5.5 at 81.8%. CyberGym tests controlled vulnerability tasks, not live production performance, so the comparison is a benchmark signal rather than deployment proof for teams deciding whether to trust AI-generated security work.
OpenAI says the cyber model scored 39.5% on ExploitGym, a benchmark for exploitation-oriented tasks, and 69.8% on SEC-bench Pro.

Earlier cyber-range tests had already made model scores a public marker for security-focused AI systems, even as AI labs still keep such advanced tools away from ordinary public access.
OpenAI lists more than 30 open-source projects in its Patch the Planet initiative, including cURL, Go, Python, Sigstore, pyca/cryptography, NATS Server, aiohttp, freenginx, and python.org. Named projects span core languages, cryptography, networking, and web infrastructure, turning the program into a public test of whether AI-assisted security work can meet project-level review standards.
Competitors, Guardrails, and the Risk Window
Against Anthropic, the comparison has immediate counterweight because the June 12 U.S. order led the company to disable Mythos access for all customers. OpenAI’s approach stays closer to its earlier approved defensive work strategy.
The Daybreak partner program is the route to supervised access. The current partner network includes more than 25 security firms and several governments, giving OpenAI a controlled distribution channel for testing the model outside its own labs without releasing the capability broadly.
Canada’s federal cybersecurity agency warned in May that AI-assisted exploitation can compress the time vendors and defenders have to respond. In Daybreak’s case, that risk creates a strict operating condition: faster model findings help only when validation, responsible disclosure, and code review move quickly enough to close the window opened by the finding.
“Organizations should assume that AI-driven exploitation may bypass preventative controls, significantly outpace vendors’ capacity to publish corrective measures and challenge the organization’s ability to deploy.”
Canadian Centre for Cyber Security, Government cybersecurity agency
For Daybreak, benchmark leads over Mythos will draw attention, but accepted code changes in projects such as cURL, Go, Python, Sigstore, and pyca/cryptography will decide whether GPT-5.5-Cyber becomes more than a controlled-test result.



