

- Code Authorship: Anthropic says Claude now writes more than 80% of code merged into its production systems.
- Review Risk: The disclosure shifts the enterprise question from whether AI can generate code to whether teams can review, test, and approve it safely.
- Autonomy Caveat: Anthropic still frames full recursive self-improvement as a future possibility, not something Claude has already achieved.
- Control Gates: Teams using AI coding agents need audit trails, security checks, rollback paths, and human approval before AI-authored code reaches production.
Anthropic says Claude wrote more than 80% of the code it merged in May 2026, turning its own engineering workflow into a test of AI coding at production scale. For enterprise teams, the disclosure moves the practical question from whether models can generate code to whether review, security testing, and approval gates can keep pace before AI-written changes reach live systems.
Engineers remain inside the loop. They choose the work, review generated changes, and decide what is merged. Anthropic says code shipped per engineer per quarter has increased eightfold from its 2021-2025 baseline, a gain it connects to a broader self-optimizing loop in which AI helps build and test AI systems. For now, that loop still runs through human review before production code lands.
How Claude Changed Anthropic’s Engineering Loop
Claude Code is the product behind that shift. What began as a coding agent now feeds Anthropic’s own production workflow, with engineers reviewing model-written changes before merge. The tool has also become a successful commercial developer product, so the same control problem follows enterprise customers: generated code needs a clear path through review, security checks, and approval before it reaches production.
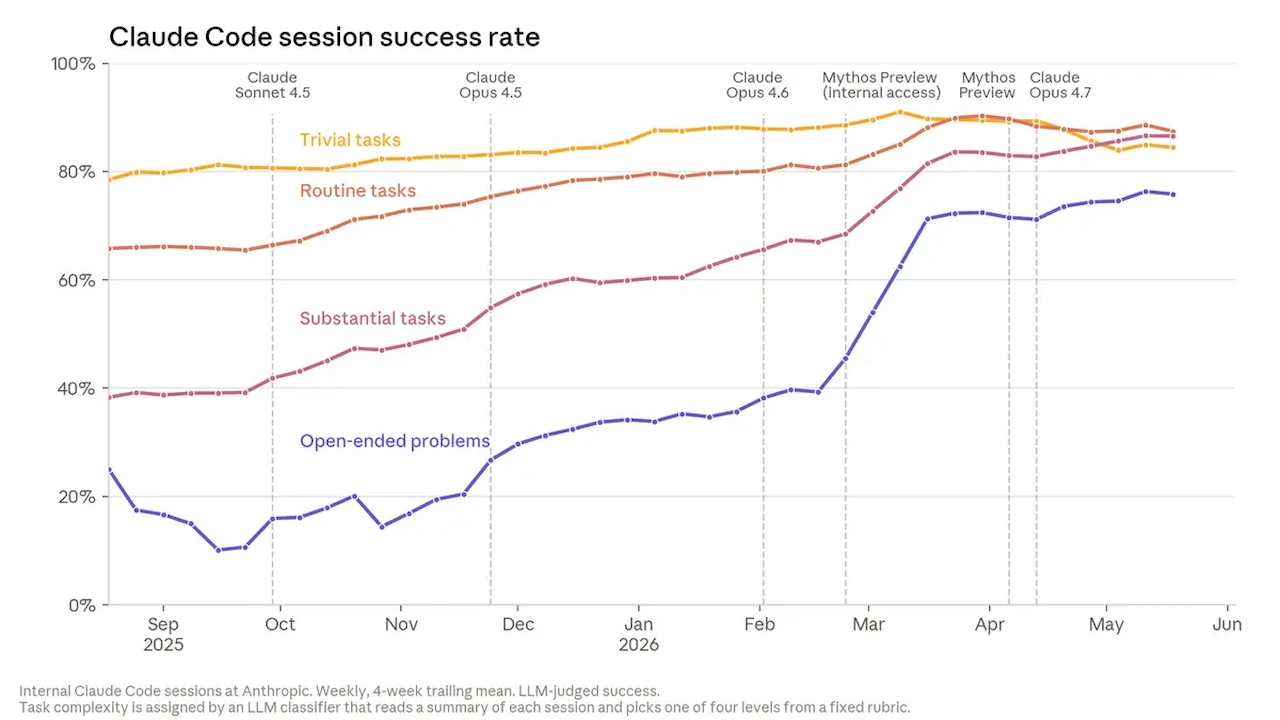
Anthropic says Claude’s success rate on its most open-ended internal engineering tasks reached 76% in May after a 50-point rise over six months. That helps explain why the company is treating AI coding as a development loop, but the remaining human role is still larger than checking syntax or approving volume. An employee quoted by Anthropic described that advantage as “seeing the bigger picture” beyond the immediate task.
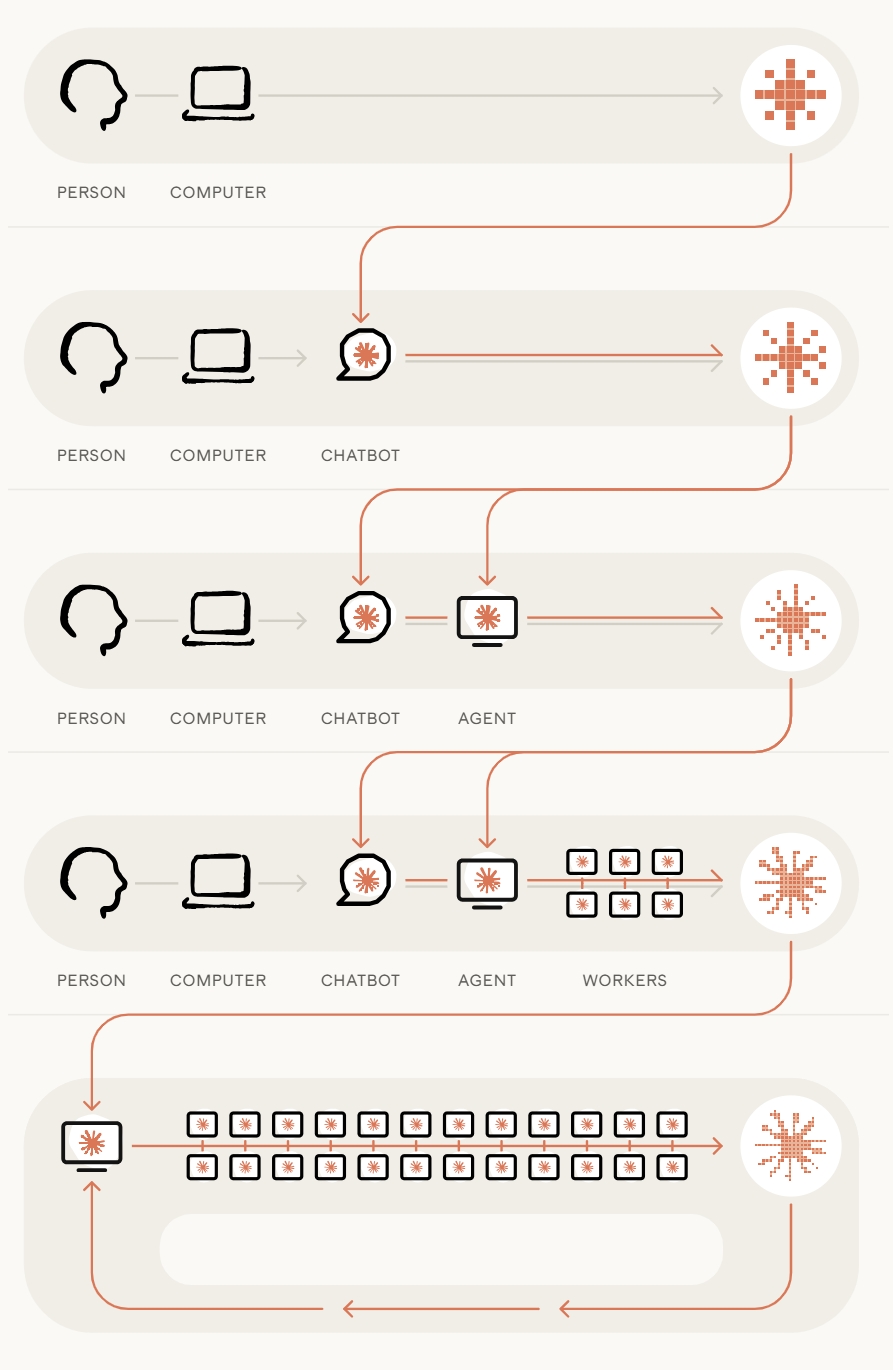
Control now depends on review capacity as much as generation speed. Anthropic’s current internal workflow uses an automated reviewer to inspect proposed code changes for bugs, security flaws, and other defects before merge. Claude Code also asks for permission before modifying files or running commands.
Local tools, developer approval, and merge discipline remain part of the workflow. Humans remain responsible for goals, approvals, and production risk even as the model supplies more of the code itself.
An April internal repair project illustrates the mechanism in practice: Anthropic says one engineer used Claude to ship more than 800 fixes for persistent API errors and reduce the error rate by a factor of 1,000.
Validation Becomes the Bottleneck
That broader human judgment matters because Anthropic’s output metrics do not settle quality. The 80% authorship claim and 76% internal task-success rate show how much Claude can contribute inside Anthropic’s workflow; they do not show that generated changes are automatically safe, maintainable, or ready to merge. January benchmark tracking by Margin Lab found a 4.1% Claude Code performance decline over 30 days, showing why code volume and reliability have to be judged separately.
Once AI-written changes enter proprietary repositories, validation becomes the constraint. Teams still have to inspect the change, test it, scan for security flaws, control permissions, and preserve rollback paths before production deployment. Anthropic’s March Claude Code Review launch automates some checks before merge, but enterprises still need people accountable for what gets approved and what happens after it ships.
Security Raises the Cost of Bad Validation
The same validation problem becomes more serious when Anthropic connects AI coding work to security. Mythos Preview, the publicliy unreleased model Anthropic is using for code and security research, reportedly reached a 52x speedup on an internal training-code optimization benchmark. Anthropic’s Project Glasswing already put Mythos Preview into defensive security work, giving partners and more than 40 organizations access and identifying more than 10,000 high-severity or worse software vulnerabilities.
This shows why review quality matters beyond Anthropic’s own repositories. CrowdStrike’s Elia Zaitsev alreadz warned that vulnerability timelines are compressing, saying that “what once took months now happens in minutes” with AI. In that market, GitHub Copilot, Cursor, OpenAI Codex, and Google Gemini Code Assist give users alternatives, but the practical comparison is the same: which tools can pair code generation with review logs, security checks, rollback paths, and human approval before AI-written changes reach production.



