
“Most analytic queries aggregate large amounts of data and are served well by scanning the column store segments directly,” writes Microsoft senior program manager Shivani Gupta
“However, there is often a need to look for a ‘needle in a haystack’ which translates to a query that does a lookup of a single row or a small range of rows,” Gupta adds. “Such look-up queries can get orders of magnitude (even 1000x) improvement in response time and potentially run in sub-second if there is a B-Tree index on the filter column.”
Until now, users had to duplicate column store data in a clustered B-Tree index to meet response time requirements for their lookup queries. Still, the duplication of data added an unnecessary level of complexity, as well as storage cost and latency.
Microsoft states that some of the users had an opportunity to test the new feature. They are more than pleased that they can get the same interactive response time without the data duplication.
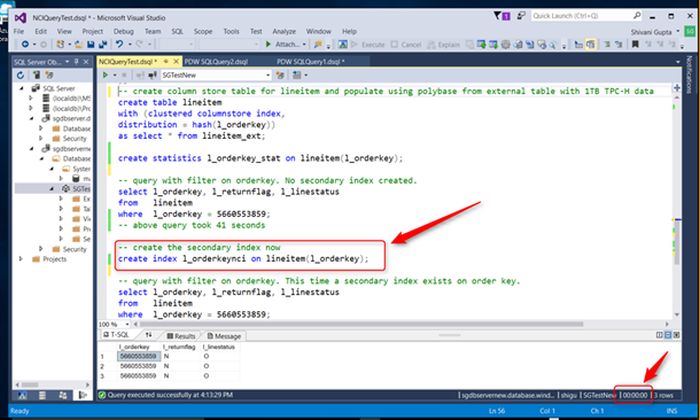
Image credit: Microsoft
Users should have no problem creating a secondary index (also referred to as non-clustered indexes or NCI) on a column store table (also referred to as clustered column store indexes or CCI). The process follows the same syntax as the generic Create Index Transact-SQL statements.
The blog post also explains the best practices for using secondary indexes on column store tables.
- Use them for high cardinality columns that are used as filters in queries returning a small number of rows.
- Don’t be heavy handed with secondary indexes as there is an overhead to maintaining them during loads. Best to limit to 1 or 2 secondary indexes per table.
Additionally, users can create secondary indexes on partitioned column store tables. However, because these are local to each distribution and partition, implementing UNIQUE constraint is not an option.
Azure SQL Data Warehouse is the go-to SQL data tool
Azure SQL Data Warehouse is a cloud service that combines a SQL Server relational database with Azure cloud scale-out capabilities. It also takes full advantage of the Azure platform with easy deployment, seamless maintenance, and automatic back-ups.
Thanks to its massively parallel processing (MPP) distributed database system, the service offers massive scalability. This makes it ideal to handle any enterprise workload while saving costs along the way.


